Build a web scraper for sever-side rendered HTML with JavaScript
Last modified March 28th 2022 |
![]() Source Code [GitHub]
|
#js #node
Source Code [GitHub]
|
#js #node
“Scraping” can be used to collect and analyse data from sources that don’t have API’s. In this tutorial we’ll be using JavaScript to build a web scraper from a website that’s been rendered server-side. If you’re looking learn about or interested in scraping client-side rendered data we’ve also got a tutorial for that here.
You’ll need to install Node.js and npm if you haven’t already.
Let’s start by creating a project folder and initialising it with a package.json file:
mkdir scraper
cd scraper
npm init -yWe’ll be using two packages to build our scraper script.
- axios – Promise based HTTP client for the browser and node.js.
- cheerio – Makes it easy to work with the DOM (similar to jQuery).
Install these packages by running the following command:
npm install axios cheerio --saveNext create a file called scrape.js and import the packages we just installed:
const axios = require("axios");
const cheerio = require("cheerio");Code language: JavaScript (javascript)In this example we’ll be using Hacker News as the data source to be scraped.
When Inspecting the source code you’ll see that the site name in the header has a hnname class. Let’s write a test script to see if we can fetch the source code (without being blocked) and grab the site name text.
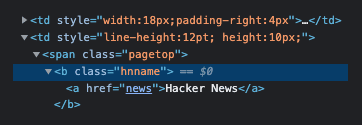
Add the following to scrape.js to fetch the data and log the text if successful:
axios('https://news.ycombinator.com/')
.then((response) => {
const html = response.data;
const $ = cheerio.load(html);
const title = $(".hnname a").text();
console.log(title);
})
.catch(console.error);Code language: JavaScript (javascript)Run the script and you should see Hacker News logged in the terminal:
node scrape.jsCode language: CSS (css)If everything’s working we can proceed to scrape some actual content from the website.
Let’s get the titles, domains and points for each story on the homepage:
axios("https://news.ycombinator.com/")
.then((response) => {
const html = response.data;
const $ = cheerio.load(html);
const storyItem = $(".athing");
const stories = [];
storyItem.each(function () {
const title = $(this).find(".titlelink").text();
const domain = $(this).find(".sitestr").text();
const points = $(this).next().find(".score").text();
stories.push({
title,
domain,
points,
});
});
console.log(stories);
})
.catch(console.error);
Code language: JavaScript (javascript)This code loops through each of the athing table rows, grabs the data, and then saves it in to an array called stories. If you’ve worked with jQuery before then the selectors used to grab the text will be familiar, if not you can learn about them here.
Now re-run node scrape.js and you should see the data for each of the stories:

Hopefully this tutorial has provided you with all the information you need to scrape client-sided rendered websites using JavaScript. As mentioned in the intro you can also find a tutorial on scraping server-side rendered content here.
Related Posts
#AD Shop Web Developer T-Shirts



